
Federated scientific machine learning for approximating functions and solving differential equations with data heterogeneity
Published in IEEE Transactions on Neural Networks and Learning Systems, 2024
Abstract
By leveraging neural networks, the emerging field of scientific machine learning (SciML) offers novel approaches to address complex problems governed by partial differential equations (PDEs). In practical applications, challenges arise due to the distributed essence of data, concerns about data privacy, or the impracticality of transferring large volumes of data. Federated learning (FL), a decentralized framework that enables the collaborative training of a global model while preserving data privacy, offers a solution to the challenges posed by isolated data pools and sensitive data issues. Here, this article explores the integration of FL and SciML to approximate complex functions and solve differential equations. We propose two novel models: federated physics-informed neural networks (FedPINNs) and federated deep operator networks (FedDeepONets). We further introduce various data generation methods to control the degree of nonindependent and identically distributed (non-i.i.d.) data and utilize the 1-Wasserstein distance to quantify data heterogeneity in function approximation and PDE learning. We systematically investigate the relationship between data heterogeneity and federated model performance. In addition, we propose a measure of weight divergence and develop a theoretical framework to establish growth bounds for weight divergence in FL compared with centralized learning. To demonstrate the effectiveness of our methods, we conducted ten experiments, including two on function approximation, five PDE problems on FedPINN, and four PDE problems on FedDeepONet. These experiments demonstrate that proposed federated methods surpass the models trained only using local data and achieve competitive accuracy of centralized models trained using all data.
Main idea
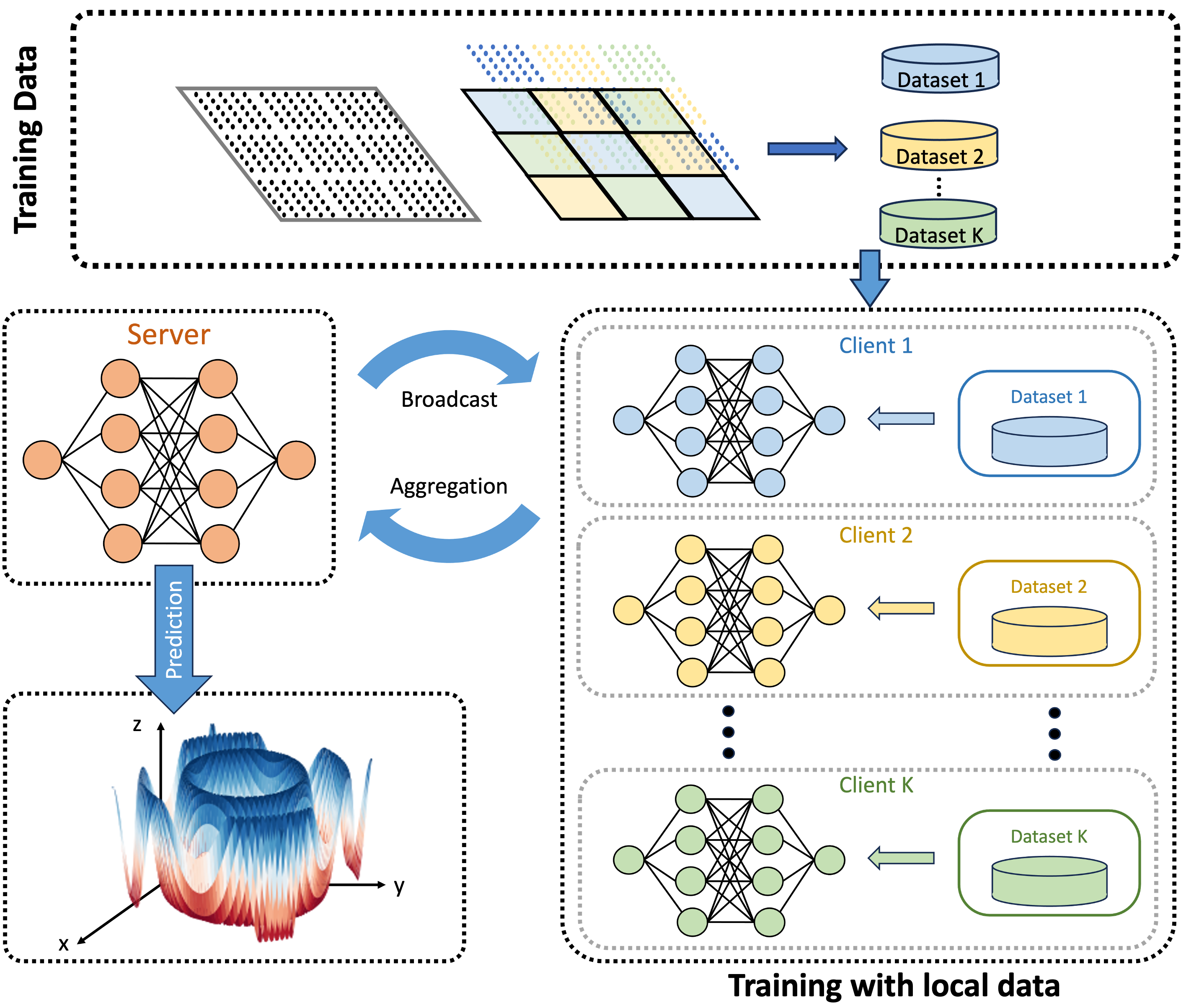
In FedSciML, each client has its model and dataset. The models are trained through a collaborative training procedure, which includes (1) the aggregation from local models to the server model and (2) the broadcast from the server model back to local models.
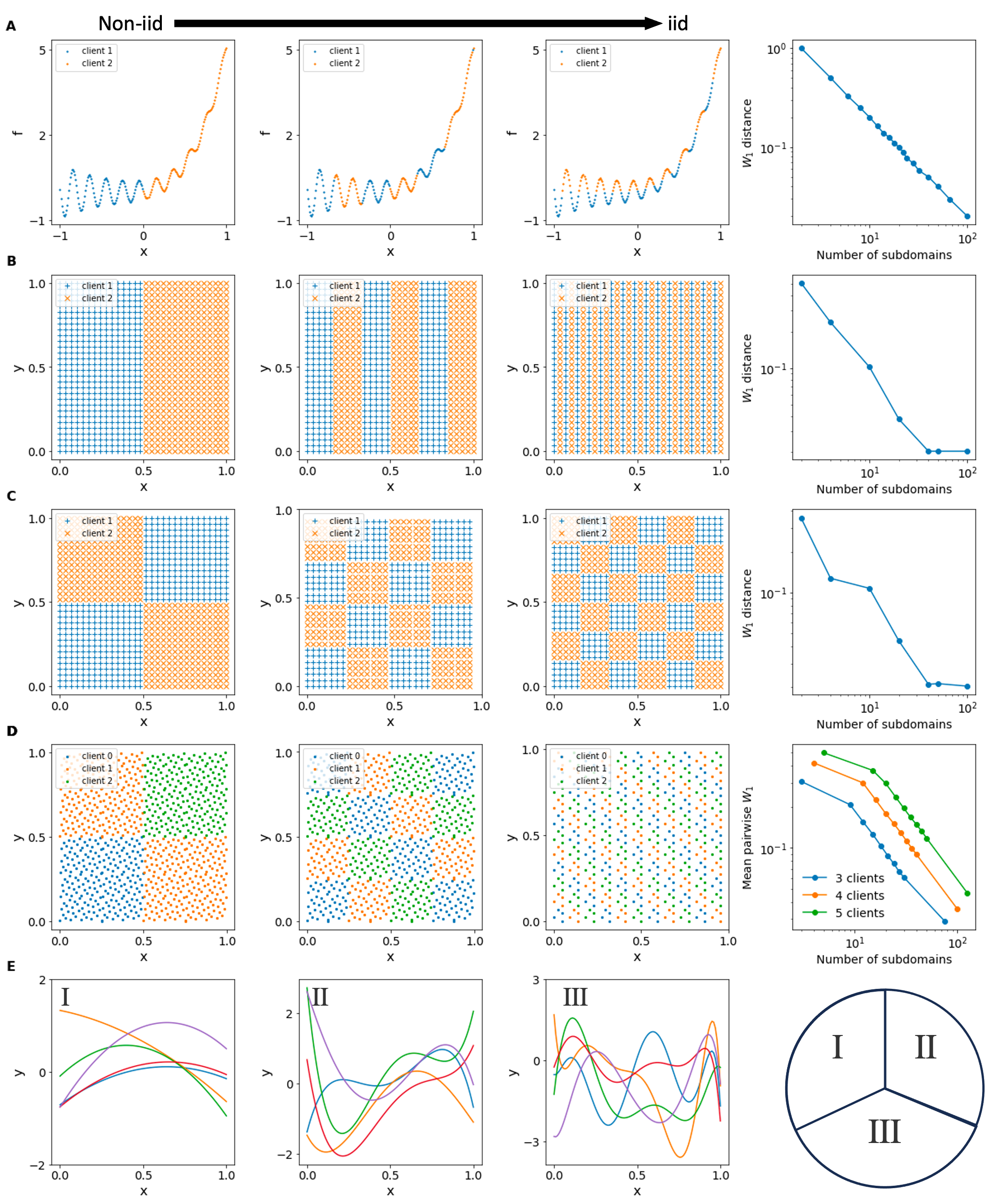
We generate controllable non-IID datasets to study data heterogeneity in federated scientific machine learning. For function approximation and PDE problems, data are partitioned across clients using 1D partitions, 2D (x)-partitions, or 2D (xy)-partitions. For operator learning, data heterogeneity is introduced by assigning clients input functions generated from different subsets of Chebyshev basis functions. The 1-Wasserstein distance (W_1) is used to quantify the discrepancy between client data distributions.
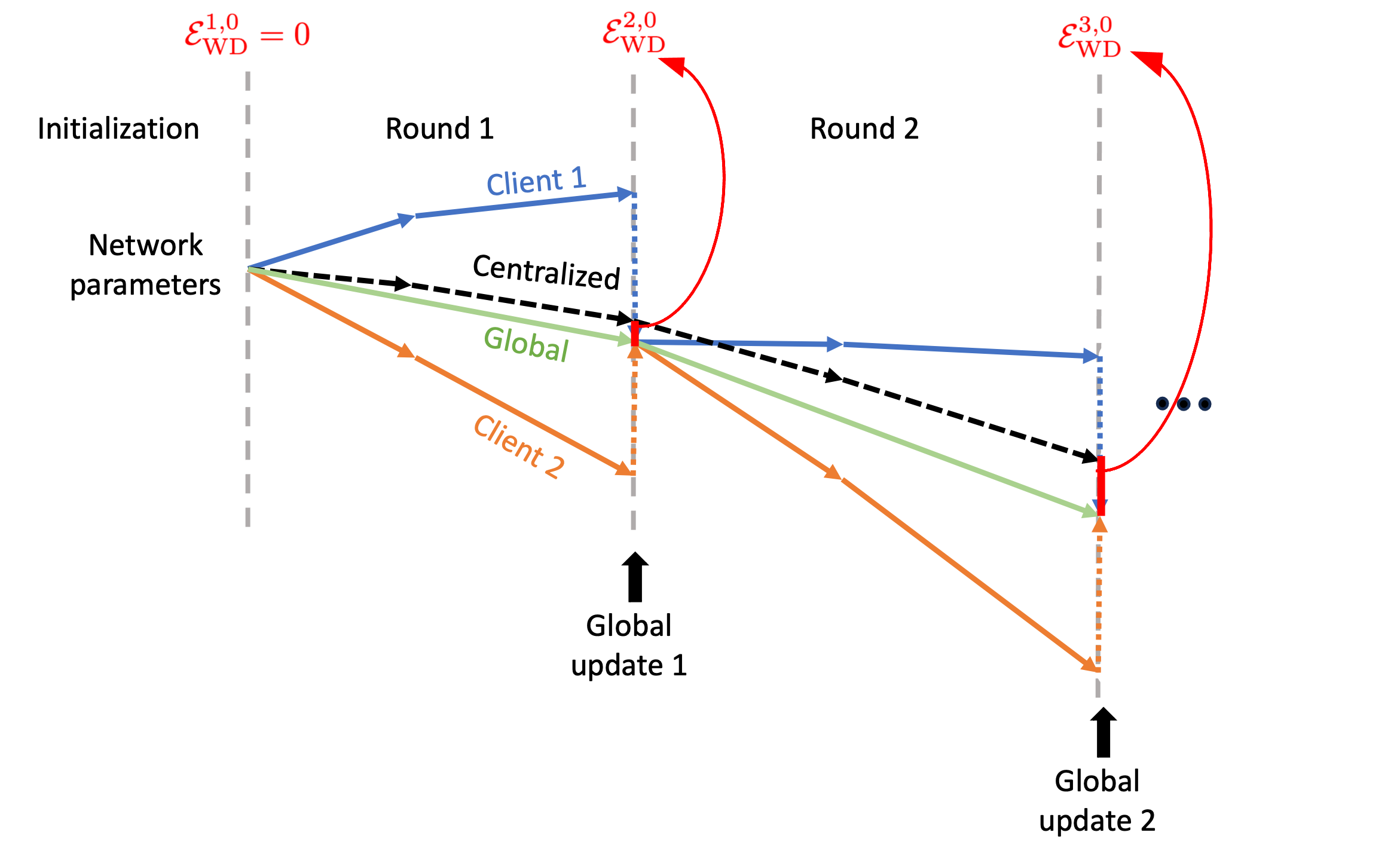
The black dashed line represents the gradient descent for the centralized model. The blue and orange lines correspond to the gradient descents for two clients in federated learning, while the green line depicts the gradient descent of the global model using the FedAvg algorithm.